Introduction



Data management service that brings continuous data validation to tabular data in your repository via Github Action. It is a minimalistic integration between Github Actions and Frictionless Data. In this introduction we will show how it works and describe the projects it relies on. Let's get started and here is a example of a validation report provided by Frictionless Repository:
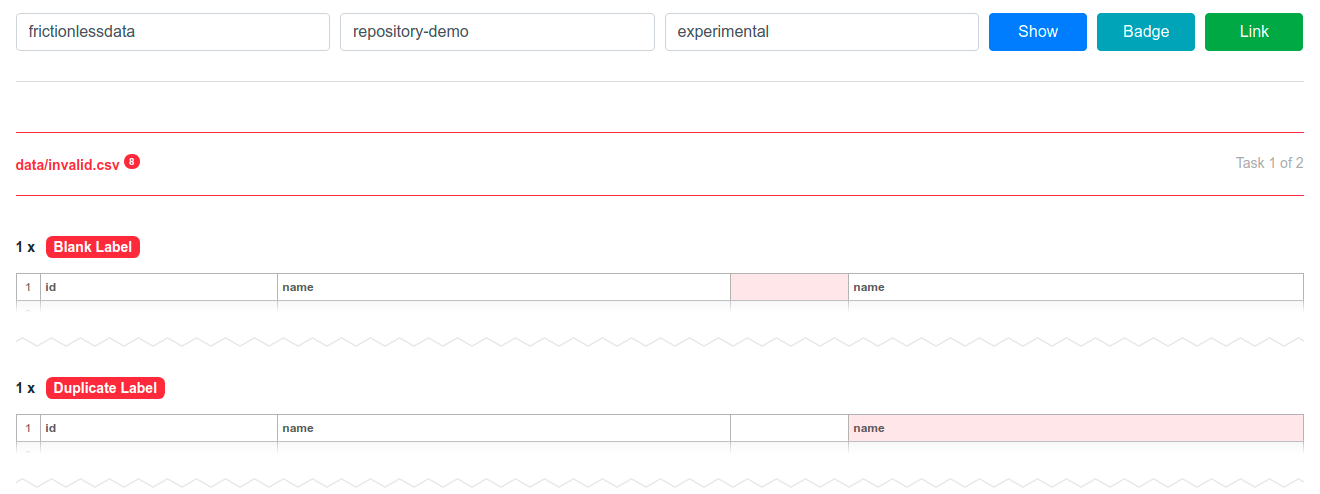
How It Works#
On every commit to your repository there will be run a validation process to find tabular errors and other problems in your data. We created a demo video to introduce a basic workflow of continious data validation using Frictionless Repository:
Github Actions#
Github Actions is a continuous integration service. If you're not familiar with Github Actions we really recommend you to watch a short talk given by Grant R. Vousden-Dishington on csv,conf,v6:
Frictionless Data#
Frictionless Data is a comprehensive data software and standards project covering many aspects working with data. Frictionless Repository uses a Python framework to validate data and a report component to show the validation results:
Frictionless Repository can be described by this simple flow:
- you add a Frictionless Repository step to their workflow on Github
- Frictionless Framework validates your data and saves the result as a workflow's artifact
- Frictionless Components fetch and render this validation report
Frictionless Repository is completely server-less so it doesn't rely on any third-party hardware except for Github infrastructure. There is no vendor-lock or something like this a you can fork this project and run it on Github differently if needed.